
While Linux is a great operating system, many applications are not available in its ecosystems, such as iTunes, OneNote or Sony Digital Paper. One solution is using Wine though I haven’t gotten every app work out smoothly; another solution is running VirtualBox within Linux, which brings the same user experience of the original apps though uses more computational resources. This tutorial covers setting up Mac OS virtual box in Ubuntu (18.01), my guide follows this useful article.


Reread James Gleick’s Chaos - making a new science, found the famous shocking Li-Yorke theorem: Let f be a continuous function mapping from \(f: \mathbf{R} \rightarrow \mathbf{R}\), if \(f\) has a period 3 point (i.e. \(f^3(x) = x\) and \(f(x), f^2(x) \neq x\)), then
For every \(k = 1,2,...\) there is a periodic point having period \(k\).
There is an uncountable set S containing no period points, which satisfies
Bring beautiful natural scenery to every new tab in Chrome! Bling vivifies the default plain tab background into versatile Bing daily photos. Minimal permission required.

Scenario: Keymapping for specific apps in Mac.
For example, Windows and Mac use control/ command keys differently, it becomes annoying when using Microsoft Remote Desktop on Mac doesn’t provide a self-contained working environment, it often jumps to other mac apps easily. Map the mac command key to control key sort out the problem.
My weekend chrome extension project: Enlighten - a handy syntax hightlighting tool based on hightlight.js, try it on Chrome Web Store or check out the source code. Any feedback will be appreciated!

Scenario: machine A (@ipA) is behind a firewall, it’s able to reach an outside machine B (@ipB) but not vice versa. We’d like to make B able to reach A.
Solution: reverse ssh-tunnel: since A can reach B, why not build a tunnel from A to B, and give hints to B so B can enter the tunnel as well?
ssh -R 1234:localhost:22 userB@ipBssh userA@localhost -p 1234Automatic run when reboot:
sudo apt-get install audossh.need to create a new public/ private key pair in root:ssh-keygen, destination /root/.ssh/id_rsa.
autossh -M 12345 -o "PubkeyAuthentication=yes" -o "PasswordAuthentication=no" -i /root/.ssh/id_rsa -R 1234:localhost:22 userB@ipB.Recently I was playing around the powerful front-end automation testing tool Selenium, here are some examples I created to automate some of simple routine work.
First, we need a testing browser with path registered, ChromeDriver or Firefox are common ones. Typically put the executable chromedriver in /usr/local/bin/chromedriver (or chromedriver.exe in C:/Users/%USERNAME/AppData/Local/Google/Chrome/Application/), don’t forget to register this path or specify when using it.
#sudo apt-get install unzip
wget -N https://chromedriver.storage.googleapis.com/2.38/chromedriver_linux64.zip
unzip chromedriver_linux64.zip
chmod +x chromedriver
sudo mv -f chromedriver /usr/local/share/chromedriver
sudo ln -s /usr/local/share/chromedriver /usr/local/bin/chromedriver
sudo ln -s /usr/local/share/chromedriver /usr/bin/chromedriver
import requests
from lxml import html
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36'}
xpath_product = '//h1//span[@id="productTitle"]//text()'
xpath_brand = '//div[@id="mbc"]/@data-brand'
def getBrandName(url):
page = requests.get(url,headers=headers)
parsed = html.fromstring(page.content)
return parsed.xpath(xpath_brand) def foo(dummy, results):
results.append(dummy)
from threading import Thread
num_threads = 5
threads, results = [], []
for i in range(num_threads):
process = Thread(target=foo, args=(i, results,))
process.start()
threads.append(process)
for process in threads:
process.join()
print(results)

Stories of love, loss and redemption
Started listening to WBUR/ NPR’s Modern Love podcasts when I was in NYC, it becomes one of my favorite podcast. Often cry when hearing love, pain, struggles, death, youth stories (while driving and cooking). Well done - authors, host Meghna Chakrabarti and the New York Times!

Once you learn how to die, you learn how to live.
So many people walk around with a meaningless life. They seem half-asleep, even when they’re busy doing things they think are important. This is because they’re chasing the wrong things. The way you get meaning into your life is to devote yourself to loving others, devote yourself to your community around you, and devote yourself to creating something that gives you purpose and meaning.
Continue Reading...The most important thing in life is to earn how to give out love, and to let it come in.
Notes on Robert C. Martin - Clean Architecture: A Craftsman’s Guide to Software Structure and Design, chapter 1-3.
The goal of software architecture is to minimize the human resources required to build and maintain the required system.
Two perspectives of software:
Inspiried by the New York Times “Is the Answer to Phone Addiction a Worse Phone?”, I wrote a chrome extension (source code) to turn some of my favorite websites into grayscale:


Looks promising! Enjoy new life without internet addiction!

A book about Google culture, management, and the authors’ success stories.
 * NLP= Ambiguity Processing
- Lexical Ambiguity: dog (noun vs verb), (animal vs detesable person), contexts.
- Structural Ambiguity
- Semantic Ambiguity
- Pragmatic Ambiguity
* NLP= Ambiguity Processing
- Lexical Ambiguity: dog (noun vs verb), (animal vs detesable person), contexts.
- Structural Ambiguity
- Semantic Ambiguity
- Pragmatic Ambiguity

This is a demo of email thread generator based from Gmail to Gmail and Outlook. It can
Prerequisite:
This is a simple example demonstrating how to run a Python script with different inputs in parallel and merge the results. Here an application is to get aggregation statistics in different dates through computationally intense queries, and merge across all dates.
from multiprocessing import Process
import pandas as pd
import os
def get_days(start, num_of_days):
''' generate a list of dates starting from the starting date
to the starting date + num_of_days
'''
date_range = pd.date_range(start, periods=num_of_days, freq='1D')
return map(lambda dt: dt.strftime("%Y-%m-%d"), date_range)
f = lambda x: os.system("python foo.py --date %s" % x)
children = []
for date in get_days(start, end):
p = Process(target=f, args=(date,))
p.start()
children.append(p)
for x in children:
x.join()
# merge results
all_df = (pd.read_csv(filename) for filename in glob.glob("*.csv"))
merge = pd.concat(all_df, ignore_index = True)
This is an application of A Neural Algorithm of Artistic Style by Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge, ran on GPU (GTX-980).
Raw photo was shoot at one of my favorite place - the St Paul’s Cathedral.

First Baroque painting style is Jan Brueghel the Elder) The Entry of the Animals Into Noah’s Ark.

Congratulations to our #NCDataJam winners NC Food Inspector!!! pic.twitter.com/DovA13G3IM
— NC DataPalooza (@NCDatapalooza) September 24, 2016
Install Spark is handy, here a quick guide on Spark installation on Mac and Ubuntu.
Download Spark 2.0 from the official website
Extract the contents:
cat /Users/<yourname>/spark.tgz | tar -xz -C /Users/<yourname>/
Create a soft link
cd /Users/<yourname>/
ln -s spark-* spark
Add shortcuts to your .bash_profile:
export SPARK_HOME=~/Users/<yourname>/spark
export PYTHONPATH=$SPARK_HOME/python/:$PYTHONPATH
.bash_profile and runBONUS:
To have similar environment like ipython/ ipython notebook, I added thesee alias in my bash_profile:
alias ipyspark='$SPARK_HOME/bin/pyspark --packages com.databricks:spark-csv_2.10:1.4.0'
alias ipynbspark='PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS="notebook --no-browser --port=7777" $SPARK_HOME/bin/pyspark --driver-memory 15g'

This is a tutorial about how to set up connect a ubuntu server (15.10) from mac (OS X).
Continue Reading...Being working on python for several years, here are some useful tricks and tools I’d like to share:
Usage: several useful tools on top of ipython notebook
First, install the extension:
git clone https://github.com/ipython-contrib/IPython-notebook-extensions.git
cd IPython-notebook-extensions
python setup.py install
then go to http://localhost:8888/nbextension/ to check which extension you’d like to use:
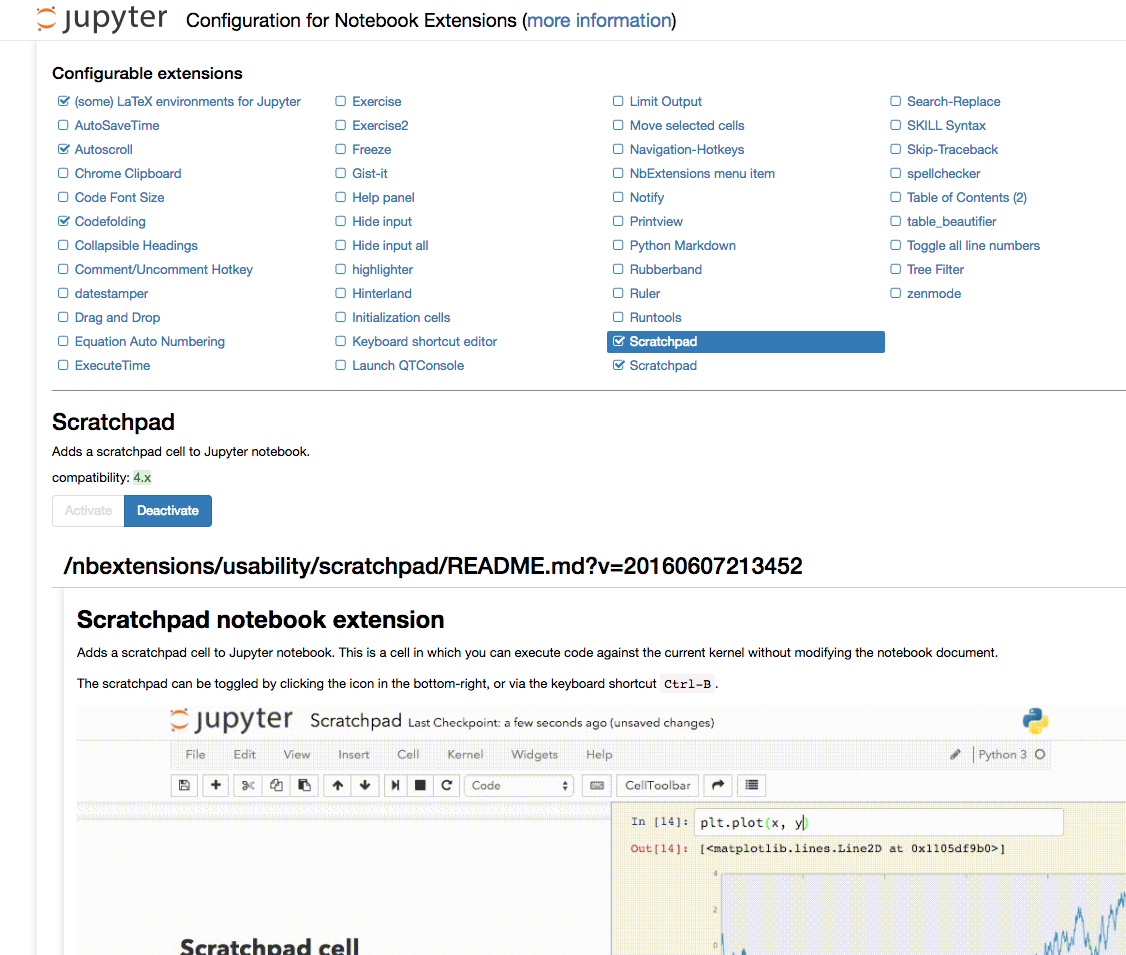 personally, I like the sketchpad very much - by typing
personally, I like the sketchpad very much - by typing ctrl+B, a scratchpad will pop up, it’s a good place for checking current variables, quick plot or run a few lines of codes without insert a cell then delete it after use. A demo looks like this:

This blog based on Jekyll is the forth website I built recently, I learned something new for every new attempts. This blog aims to share my thoughts on (but not limited to) technology and provide a place for discussions.
Continue Reading...My team Tiba won both the mHealth prize and the Grand Prize at Triangle Health Innovation Challenge
The Grand Prize goes to Tiba's physical therapy exercise tracker (also the winner of the @validic prize!) #thinc pic.twitter.com/seb5KRJ39c
— THInC (@THINCweekend) September 20, 2015
The @validic mHealth prize goes to Tiba's physical therapy exercise tracker #thinc pic.twitter.com/hFOkgo1lVM
— THInC (@THINCweekend) September 20, 2015